From 4K to 1M Tokens: The Technical Journey of Long-Context LLMs
Imagine the difference between reading a single chapter versus an entire book in one sitting. That’s the leap large language models have made in just a few years — from GPT-3’s 2K tokens to today’s models handling over a million tokens. This represents fundamental breakthroughs in computer science that make processing entire codebases, legal documents, and multi-hour conversations possible.
📚 What You’ll Learn
- The Core Problem — Why context length was limited and the quadratic attention bottleneck
- Architectural Breakthroughs — Flash Attention, sparse patterns, and alternative architectures
- The KV Cache Challenge — The hidden inference bottleneck and solutions like GQA
- Quality vs. Quantity — The “lost in the middle” problem and what it means
- State of the Art — Comparing today’s leading models
- What’s Next — Future directions in long-context AI
1. The Core Problem: Quadratic Attention
The Bottleneck
Standard transformer self-attention computes relationships between every pair of tokens:
Attention(Q, K, V) = softmax(QK^T / √d_k)VFor a sequence of length n:
- Memory: O(n²) for attention scores
- Compute: O(n²d) operations
Real-world impact:
- 4K tokens → ~16 million attention scores
- 100K tokens → ~10 billion attention scores (625x increase!)
- 100K context at fp16 → ~20GB just for attention matrices
This made long contexts impractical with naive implementations.
2. Architectural Breakthroughs
Flash Attention: The Memory Revolution
Core insight: Don’t materialize the full attention matrix in GPU memory.
How it works:
- Tile-based computation using fast GPU SRAM instead of slow HBM
- Fuses operations to avoid storing intermediate results
- Recomputes during backward pass
Impact:
- 2–4x speedup
- Memory drops from O(n²) to O(n)
- Enabled 10x longer sequences on same hardware
# Standard: Creates massive [n, n] matrix
attention_scores = Q @ K.T # Doesn't scale!# Flash Attention: Block-wise, never stores full matrix
for block_q in Q_blocks:
for block_k, block_v in zip(K_blocks, V_blocks):
block_output = compute_attention_tile(block_q, block_k, block_v)
accumulate(block_output) # O(n) memorySparse Attention Patterns
Philosophy: Not all tokens need to attend to all others.
Sliding Window Attention (Mistral, Longformer)
- Each token attends only to nearby tokens (e.g., window of 4096)
- Complexity: O(n × W) instead of O(n²)
- Trade-off: Local context preserved, limited long-range dependencies
Other patterns:
- Strided attention — Attend to every k-th token for global context
- Random attention (BigBird) — Local + random + global tokens
- All maintain O(n) or O(n log n) complexity
Positional Encoding: RoPE & Interpolation
Problem: Traditional position embeddings don’t extrapolate beyond training length.
RoPE (Rotary Position Embeddings):
- Encodes relative positions through rotation matrices
- Naturally extrapolates to longer sequences
- Used in Llama, Mistral, most modern LLMs
Position Interpolation:
- Simple technique to extend context 10–25x
- Compress position indices to fit within trained range
- Enabled Llama 2 to go from 4K → 32K+ with minimal fine-tuning
State Space Models: A Different Paradigm
Mamba, RWKV — Radical departure from attention:
h_t = A * h_{t-1} + B * x_t # Recurrent state update
y_t = C * h_t # OutputKey properties:
- Linear complexity: O(n) vs O(n²)
- Constant memory: Fixed-size state regardless of sequence length
- Parallelizable training: Can be formulated as convolutions
Trade-off: Different inductive biases; still being researched for quality parity with transformers.
Get Jagadeesh’s stories in your inbox
Join Medium for free to get updates from this writer.
Hybrid models (Jamba) combine attention + SSM layers for best of both worlds.
3. The KV Cache Challenge
Training solved, but inference has a different bottleneck: the Key-Value cache.
What is KV Caching?
Transformers cache previous key/value computations to avoid recomputation:
# With KV cache - only compute new token
K_new = compute_keys(new_token_only)
K_cache = concatenate(K_cache, K_new) # Just append
attention = softmax(Q @ K_cache.T) @ V_cacheThe Memory Problem
KV cache = 2 × layers × kv_heads × head_dim × seq_length × precisionExample (typical 7B model, 100K tokens):
= 2 × 32 × 32 × 128 × 100,000 × 2 bytes
≈ 52 GB just for cache!At 100K+ tokens, KV cache can exceed the model weights in memory consumption.
Solutions
Grouped Query Attention (GQA) — Llama 2/3, Mistral
- Share KV heads across multiple query heads
- 4–8x KV cache reduction with minimal quality loss
# Standard: 32 query heads, 32 KV heads
# GQA: 32 query heads, 8 KV heads → 4x smaller cacheMulti-Query Attention (MQA) — Even more aggressive
- Single KV head shared across all queries
- Maximum savings, potential quality trade-off
PagedAttention (vLLM)
- Treat KV cache like OS virtual memory
- Break into fixed-size pages, can be non-contiguous
- Share pages between requests with common prefixes
- 2–4x better throughput in production
Cache Compression
- StreamingLLM: Keep first/recent tokens, evict middle
- H2O: Track and keep “important” KV pairs based on attention patterns
4. The “Lost in the Middle” Problem
Critical finding: Longer context ≠ uniformly better performance.
Needle-in-Haystack Benchmark
Insert a fact at different positions in long context, measure retrieval accuracy:
Position 0-10%: 90%+ accuracy ✅
Position 20-80%: 50-70% accuracy ⚠️
Position 90-100%: 85%+ accuracy ✅U-shaped curve — models struggle with information in the middle.
Why This Happens
- Training data bias (important info often at start/end)
- Attention dilution across very long contexts
- Position embedding artifacts
What Works
Models improving:
- Claude 2.1+ — Near-perfect retrieval across all positions
- GPT-4 Turbo — Strong improvements
- Gemini 1.5 — Good but still shows some degradation
Practical strategies:
- Place critical information at beginning/end when possible
- Use explicit instructions: “Pay attention to details throughout”
- Consider hybrid retrieval + LLM approaches for critical tasks
- Test thoroughly across different positions
5. Current State of the Art (2025)
Leading Models
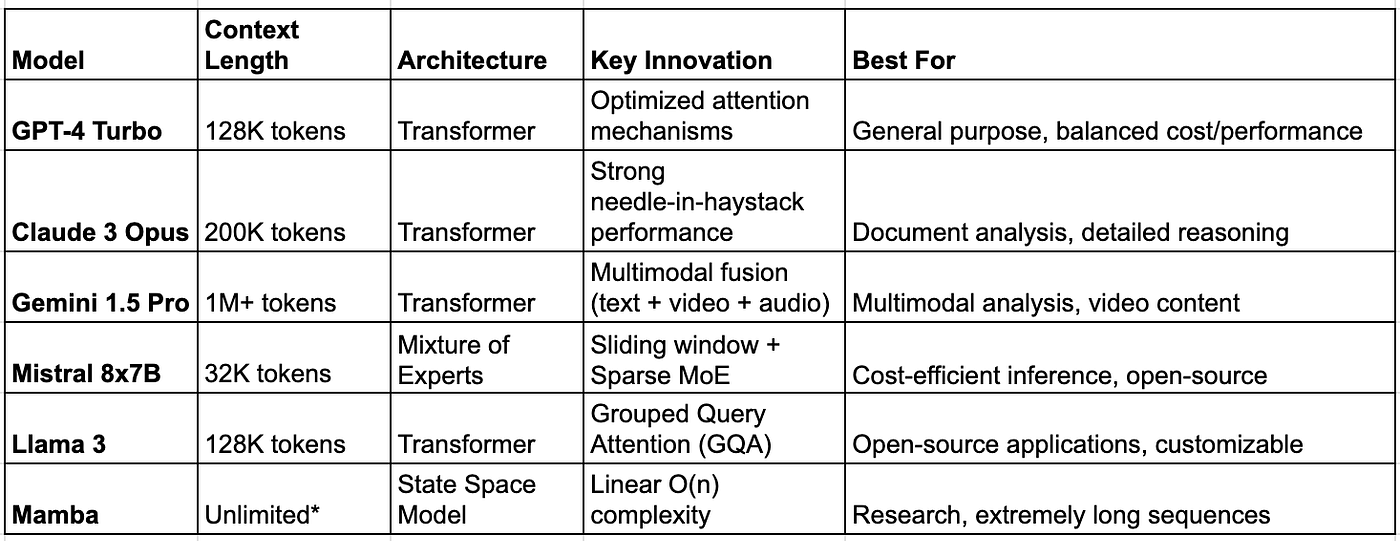
When to Use Long Context vs. RAG
Use long context when:
- Analyzing entire documents requiring full context
- Multi-turn conversations needing complete history
- Cross-document reasoning
- Codebase understanding
Use RAG when:
- Cost-sensitive applications
- Need explicit citations/sources
- Well-structured knowledge bases
- Specific information retrieval
Cost reality: 100K context ≈ 10–20x more expensive than 4K due to compute and KV cache.
6. What’s Next
Emerging Directions
Infinite context approaches:
- Learned compression of old context
- Hierarchical memory (recent/important/archived tiers)
- External memory integration with on-demand retrieval
Quality improvements:
- Uniform attention across all positions
- Faster inference at long context
- Better reasoning over long dependencies
Architectural innovation:
- Hybrid transformers + SSMs
- Adaptive context compression
- Dynamic attention budget allocation
Multimodal long-context:
- Hours of video + transcripts + documents
- Multiple meeting recordings with context
- Code + documentation + issue history
Hardware Co-Design
Next frontier: Specialized chips optimized for long-context operations, better quantization techniques, and memory hierarchies designed for massive KV caches.
Conclusion
The journey from 4K to 1M+ tokens involved breakthroughs across multiple dimensions:
Solved problems:
- ✅ Flash Attention conquered the memory wall
- ✅ Sparse patterns made computation tractable
- ✅ GQA/MQA addressed KV cache bottleneck
- ✅ RoPE enabled length extrapolation
- ✅ SSMs offered alternative O(n) architectures
Remaining challenges:
- ⚠️ Cost at scale
- ⚠️ Uniform quality across entire context
- ⚠️ Finding optimal context length for each task
- ⚠️ Making it practical for production systems
For practitioners: The tools exist. Experiment, but choose wisely — longer context is powerful but not always optimal. Consider your use case, costs, and quality requirements.
For researchers: Enormous opportunities remain in attention mechanisms, training techniques, inference optimization, and entirely new paradigms.
The 1M token barrier is broken. The next frontier is making it practical, cost-effective, and reliably high-quality.
Key References
- Dao et al. (2022) — FlashAttention: Fast and Memory-Efficient Exact Attention
- Liu et al. (2023) — Lost in the Middle: How Language Models Use Long Contexts
- Gu & Dao (2023) — Mamba: Linear-Time Sequence Modeling with Selective State Spaces
- Ainslie et al. (2023) — GQA: Training Generalized Multi-Query Transformer Models
- Kwon et al. (2023) — Efficient Memory Management for LLM Serving with PagedAttention